El framework de trabajo, conocido como data mesh, es una interesante solución al escalado de la analítica empresarial. Descubramos juntos las claves para su entendimiento.
Antes de explicar el framework conocido como data mesh, hablemos de los problemas que pretende solucionar.
Las empresas tradicionalmente están organizadas en estructuras que están divididas en departamentos que no se integran desde el punto de vista del dato. Esto lleva a la situación donde, por un lado, tenemos los datos operativos, que sirven para el funcionamiento del negocio, y por otro tenemos los datos analíticos, que sirven para optimizar el negocio.
En medio de estos dos mundos está IT, que desarrolla los procesos ETL (extracción, transformación y carga) que extraen los datos de los departamentos y se centralizan en IT. La arquitectura y el diseño de la organización refleja la divergencia que existen entre los planos operacional y analítico, donde el segundo no es capaz de proveer todas las posibilidades para obtener el valor a los datos.
En la conexión de estos dos mundos de datos, existe un cuello de botella en los procesos de ETL, que crea un flujo de datos cada vez más complejo y con problemas de escalabilidad y estabilidad.

¿Qué solución da el data mesh?
Dentro de los principales pilares en los que se fundamente el data mesh está la descentralización de los procesos ETL y la distribución de responsabilidades y gobierno del dato a las personas del negocio que están como responsables de los procesos operativos de cada tipo de dato operativo.
El data mesh cambia las arquitecturas monolíticas (DataWarehouse, Datalake, Datamarts, etc.) en un conjunto de subsistemas o dominios de datos. Cada uno de estos dominios es desarrollado por un equipo distinto. Los equipos que desarrollan los dominios están formados por un grupo de personas proveniente de cada uno de los planos, uniendo la parte operativa con la parte analítica de tal forma que el resultado sea el provisionar de datos que cumplan con las caracteríscticas de un «producto».
Estos equipos de personas se encargan de los procesos de ETL para proporcionar el dato analítico al resto de la organización.
Los dominios funcionan de la siguiente manera, cada dominio se alimenta de datos operacionales y/o analíticos provenientes de sistemas origen y/o del producto de otros dominios. Estos a su vez proporcionan datos analíticos, que también pueden ser usados por otros dominios.
Veamos el siguiente ejemplo:
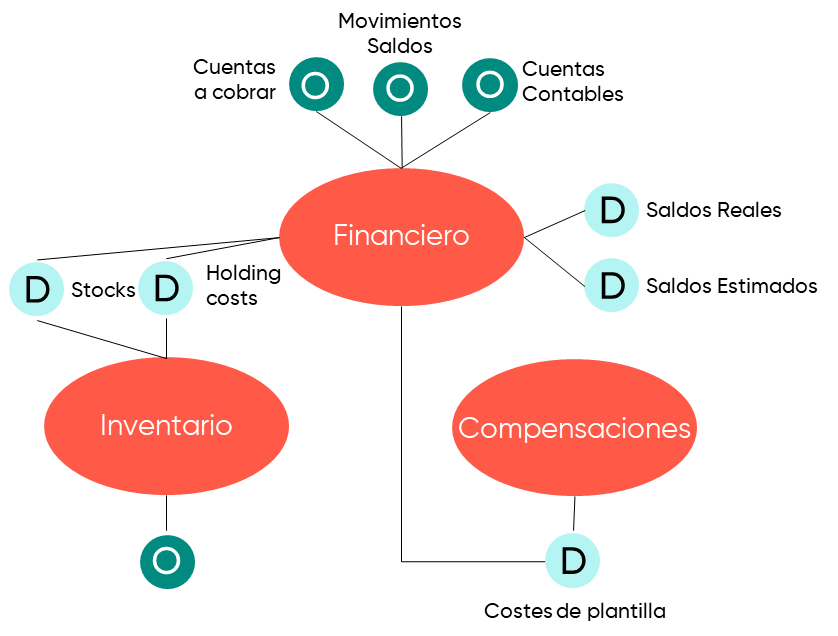
Los datos especificados como O son operacionales, es decir, los que sirven de datos de entrada en el dominio, y los especificados con D son los analíticos, los que proporcionan los dominios para consumo del resto de la organización.
La unidad de trabajo funcional en la que se fundamenta el data mesh son los dominios.
Fundamentos del data mesh
Hay cuatro principios básicos para que funcione el data mesh:
Data ownership
Este principio se basa en el control y responsabilidad sobre el conjunto de datos que el dominio proporciona al resto de la empresa. El grupo que se encarga de un dominio son los dueños del ciclo de vida del dato, tanto operacionales como analíticos.
Se descentraliza la figura del ownership, que son las personas que tiene la protestad de los datos y la adquisición, uso y política de distribución.

Data as a product
Cada dominio crea sus datos analíticos tratándolos con las características de un producto. Los «data products» se definirán en función de las necesidades de cada área y una vez creados estarán disponibles para su consumo por el resto de la organización.
Las principales características que debe tener un «data product» son tres – en primer lugar – que tenga valor intrínseco para la organización, además de que sea usable en el sentido de acceso y explotación y a su vez tiene que ser factible su construcción, en el sentido que existan los datos requeridos.

Infraestructura de autoservicio
Para desarrollar la vida del producto es necesario disponer de una infraestructura que permita la descentralización. Como cada dominio es único y está especializado, no es factible replicar una infraestructura centralizada ( Data Warehouse, etc.) n veces, por lo que es necesario disponer de una capa de infraestructura a modo de autoservicio a disposición de cada dominio.
Se definen tres capas de infraestructura a disposición de los dominios: Una primera capa de infraestructura del dato, para poder crear, administrar y mantener los data products. La segunda capa de desarrollo y por último, una capa que proporcione las funciones de acceso a los consumidores de los data product.

Gobierno computacional federado
Aunque cada dominio es independiente y funciona de una manera determinada, con sus ciclos y resultados, muchas veces va a ser necesario que estos dominios interaccionen entre ellos, para funcionar de la forma más optima posible. Por ello, aunque sean autónomas tiene que haber un equilibrio entre las decisiones que se toman internamente a nivel de dominio y las que se toman a nivel de organización.
Se requiere una normalización de los data products, para que sean entendibles y accesibles a nivel organización.
Conclusiones
Data mesh se define como un enfoque sociotécnico descentralizado para el desarrollo y gestión de datos analíticos en escala. Sociotécnico porque no es solo un framework tecnológico, sino organizativo, y en escala porque para que el framework sea diferencial se requiere que existan necesidades analíticas asociadas a una organización data driven.